Observabilidad de ingesta (Cloud Monitoring)
Hoy el equipo utiliza un dashboard en Google Cloud Monitoring para ver, en un solo lugar, cómo están funcionando los procesos de ingesta hacia solvento-data-prod: volumen de mensajes, retraso en colas, actividad de Dataflow, señales de error y tamaño de tablas en BigQuery.
Qué problema resuelve
Sin este panel, habría que saltar entre Pub/Sub, Dataflow, Cloud Run, logs y BigQuery para entender si un pipeline “está vivo” o si hay degradación. El dashboard Data Processes concentra señales operativas alineadas con cada pipeline de ingesta documentado en arquitectura (topic → job → dataset/tabla).
Dónde verlo
- Producto: Google Cloud Monitoring → Dashboards.
- Proyecto:
solvento-data-prod(métricas y logs de ingesta raw). - Nombre del dashboard: Data Processes (definición generada desde el proyecto generador; ver despliegue del dashboard).
Estado operativo actual
Este es el lugar acordado para revisar el estado en tiempo casi real de la ingesta: tráfico hacia topics, consumo/procesamiento en Dataflow, alertas visuales de lag y logs de severidad ≥ WARNING en los componentes cubiertos.
Referencia visual
El panel agrupa por origen (cabeceras de color) y por pipeline. En la captura siguiente se ve la cabecera Syntage (eventos del webhook en Cloud Run, logs con severidad ≥ WARNING y latencia p50 / p95 / p99) y el bloque Invoices (tasa de mensajes en el topic, System Lag, throughput de Dataflow en la etapa configurada, logs del job y tamaño de la tabla en BigQuery). Ese encaje permite correlacionar degradaciones —por ejemplo picos de latencia en el webhook frente a carga o errores aguas abajo en Dataflow.
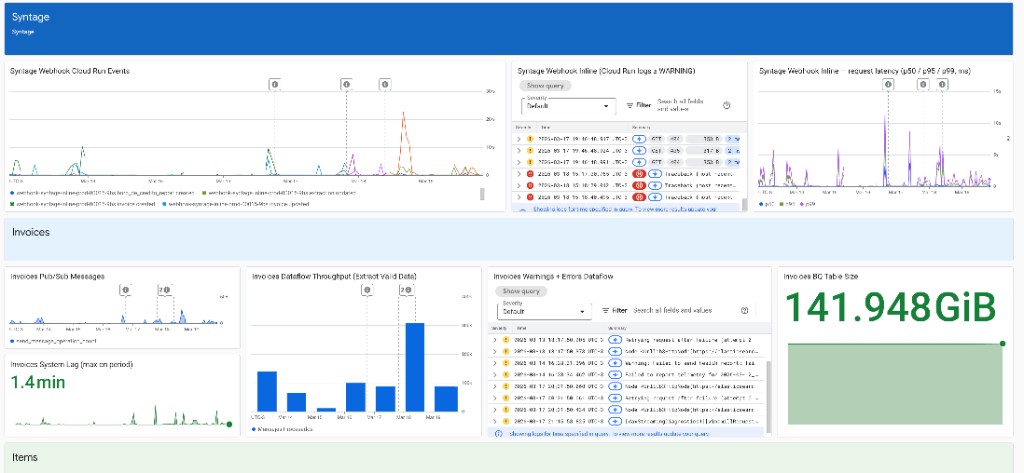
Qué muestra el dashboard (por bloque de pipeline)
Cada pipeline tiene un bloque coherente con el flujo Pub/Sub → Dataflow → BigQuery descrito en Consumo. En la práctica se combinan métricas estándar de GCP y algunas métricas derivadas de logs (custom) donde aportan contexto (por ejemplo eventos contabilizados desde Cloud Run).
| Tipo de widget | Qué indica |
|---|---|
| Pub/Sub Messages | Tasa de mensajes publicados al topic (visibilidad de carga entrante). |
| System Lag | Edad del mensaje no acuse más antiguo por región (oldest_unacked_message_age); útil para ver cuellos de botella o consumidores lentos. Umbrales orientativos en el dashboard (p. ej. warning / crítico en segundos). |
| Dataflow Throughput | Producción de elementos / escrituras según el pipeline (etapa de Beam o tipo de métrica configurado). |
| Warnings + Errors (logs) | Panel de logs filtrado a severidad ≥ WARNING en steps de Dataflow asociados al job del pipeline. |
| BQ Table Size | Bytes almacenados de la tabla de destino (métrica de almacenamiento de BigQuery; alineación temporal amplia para que la serie sea estable). |
| Cloud Run (donde aplica) | Métricas de solicitud (p. ej. latencia p50/p95/p99), logs ≥ WARNING del servicio, y gráficos basados en métricas custom desde logs para contar tipos de evento. |
Cabecera Syntage (Cloud Run webhook)
Antes de los bloques por pipeline de Syntage, el dashboard incluye una fila dedicada al servicio webhook-syntage-inline-prod (us-central1):
- Eventos reflejados en métrica custom de logging (
webhook_syntage_events). - Logs del servicio con severidad ≥ WARNING.
- Latencia de requests (distribución de Cloud Run: p50, p95, p99).
Así se separa el punto de entrada HTTP del resto del flujo (topics y Dataflow).
Pipelines reflejados en el panel
La configuración del generador agrupa visualmente por origen de datos (secciones de color) y define un bloque por pipeline. A fecha de la documentación del generador, incluye:
Origen Syntage
- Invoices (
invoices-webhook-prod→ tablas en datasetsyntage, p. ej.invoices) - Items (
items-api-topic→invoices_items) - Carta Porte (
cp-api-prod→cp_body, con layout extendido: eventos Cloud Run custom porevent_type, throughput por rutas de esquema) - Insights NRT + batch (
insights-staging-topic-prod→ datasetinsights) - Tax Compliance (
tax-compliance-api-syntage-success→tax_compliance_body) - Buró (
buro-webhook-prod→buro_body)
Origen Shinkansen
- Shinkansen Metadata (
shinkansen-payout-metadata-prod→shinkansen.shinkansen_metadata) - Shinkansen Payout Results (
shinkansen-payout-results-prod→shinkansen.shinkansen_payout_results)
Origen XML / svc_master_public
- xml_data (
bucket-xml-parser-prodCloud Run →svc_master_public.xml_data): no usa Pub/Sub ni Dataflow; el dashboard expone directamente eventos del servicio vía métrica custom, logs ≥ WARNING y tamaño de la tabla destino.
La lista exacta de topics, jobs y tablas puede evolucionar; la fuente de verdad de la composición del dashboard es el código generador (ver despliegue).
Relación con el resto de la documentación
- Flujos de ingesta por componente: Consumo, Arquitectura 5.0 (Syntage), Shinkansen.
- Filosofía de proyecto raw: Proyectos GCP.
Mantenimiento del dashboard
La definición en JSON del dashboard se regenera desde código Python; no se edita a mano el layout en la consola de forma definitiva sin riesgo de drift. Procedimiento: Cloud Monitoring — dashboard Data Processes.